Databricks
Polytomic connects to a specific Databricks warehouse using the server hostname and HTTP path.
To determine the settings for your warehouse, log into your Databricks workspace. In the sidebar, click SQL > SQL Warehouses. Click the name of the warehouse you want to use with Polytomic. The Connection Details tab contains the hostname, port, and HTTP path, which you'll enter in Polytomic.
Polytomic authenticates to Databricks using a Personal Access Token. See the Databricks documentation for details on generating a token.
Configuring the connection
- In Polytomic, go to Connections → Add Connection → Databricks.

-
Enter the server hostname, port, access token (if you need OAuth authentication instead, see next section), and HTTP path.
-
If you don't have Unity Catalog enabled on your Databricks cluster, make sure to unmark the Unity Catalog enabled checkbox.
-
Click Save.
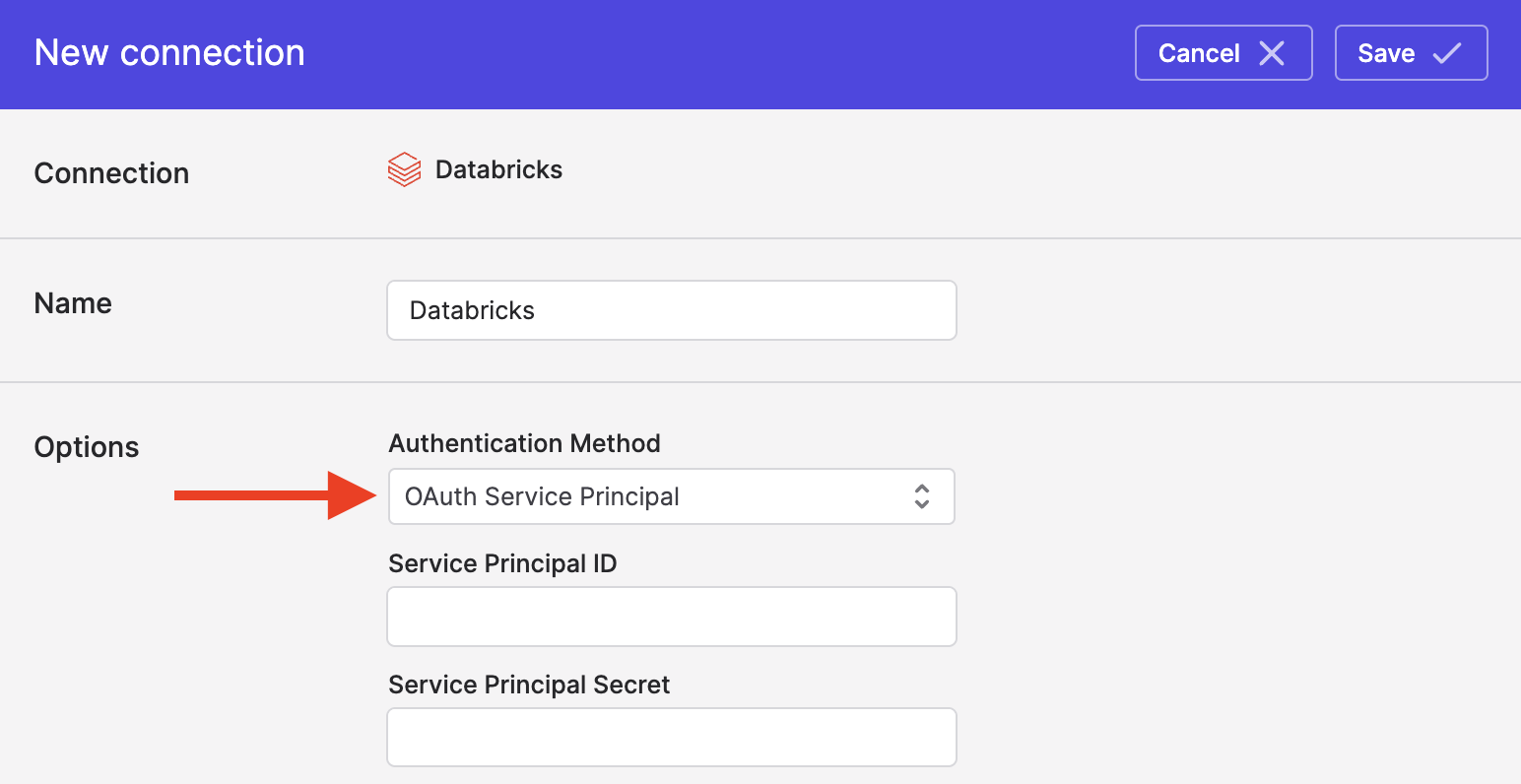
Authenticating with OAuth
To use OAuth authentication, change your Authentication Method above to OAuth Service Principal:
Writing to Databricks
If you'd like to also write to Databricks, you'll need to select your cloud provider and provide its access settings:
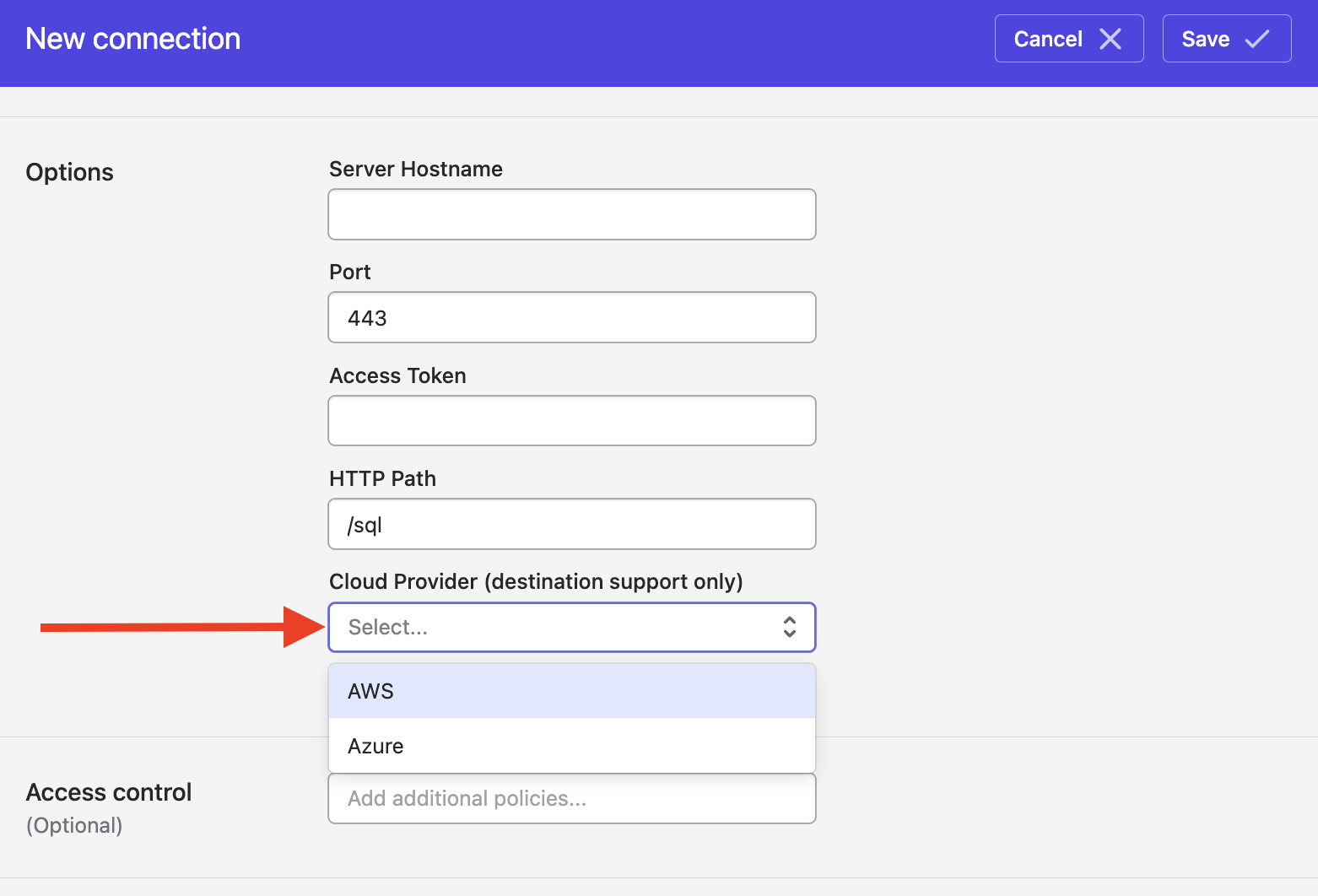
Writing to Databricks on AWS
(For connecting to Databricks on Azure, see the next section.)
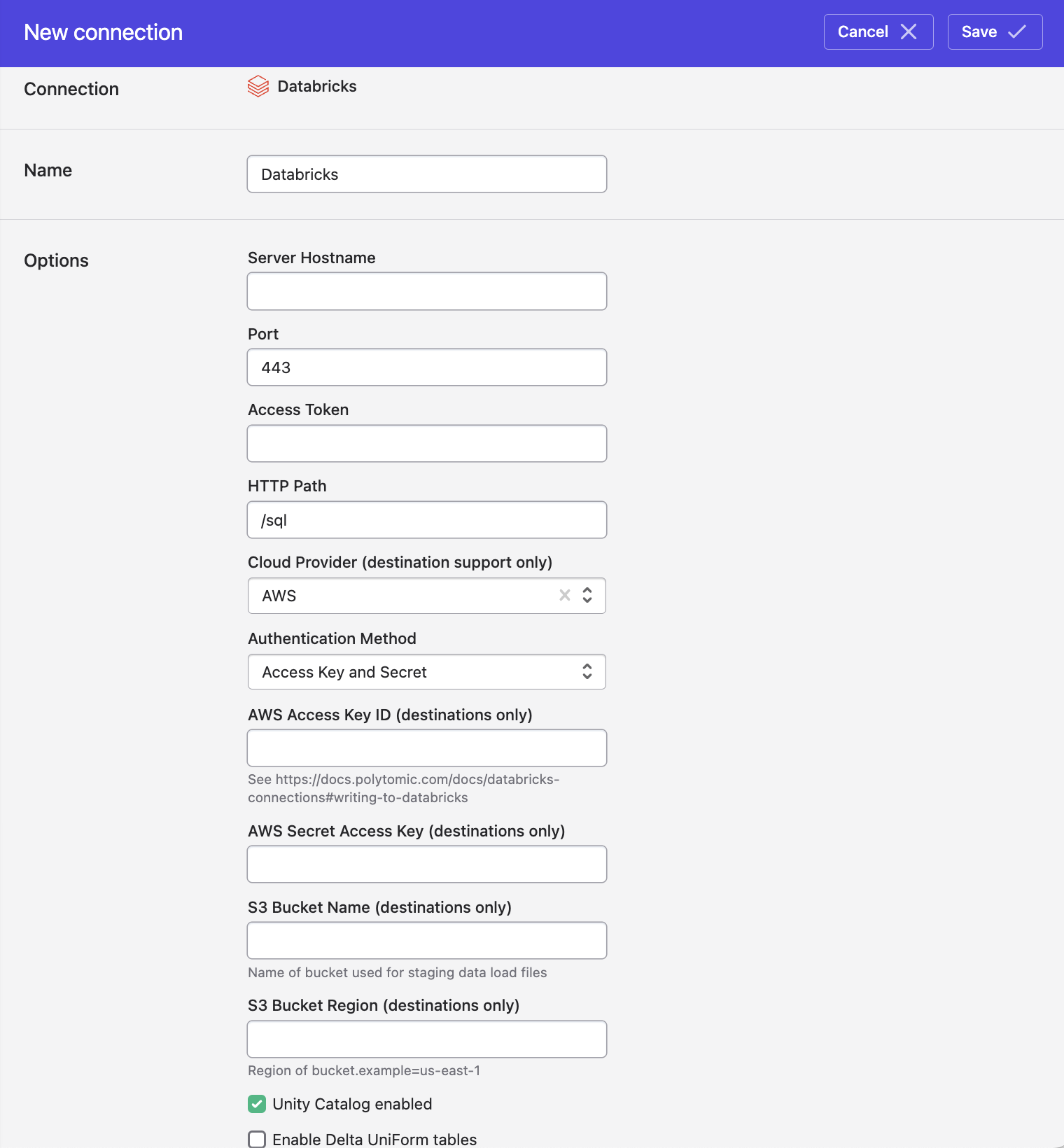
To enable Polytomic to write to your AWS Databricks cluster, you'll need to provide the following information:
- AWS Access Key ID.
- AWS Secret Access Key.
- S3 bucket name (Polytomic uses an S3 bucket to stage data for syncs into Databricks).
- S3 bucket region (e.g.
us-east-1or such). - Either:
- An AWS Access Key ID and Secret, or
- An AWS IAM Role ARN which Polytomic will assume when staging data into the bucket.
Using an AWS IAM Role to stage data for Databricks
If you're on AWS and require authenticating using an IAM role rather than an access key and secret, see instructions here.
Writing to Databricks on Azure
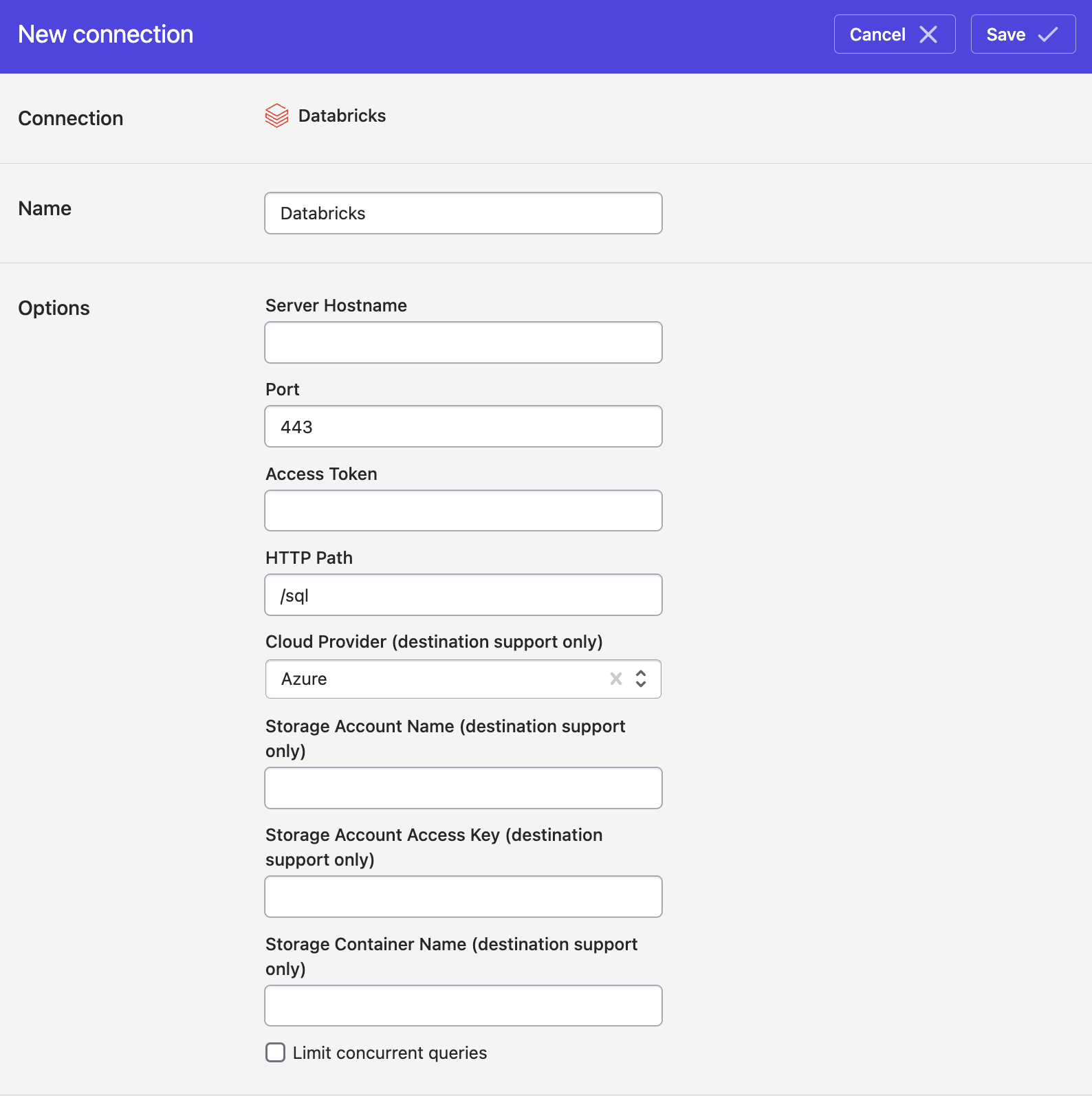
To enable Polytomic to write to your Azure Databricks cluster, you'll need to provide an Azure Storage container for us to stage data in.
Azure Storage Account TypeDatabricks requires that your Azure storage account is Data Lake Gen2 compatible. For this reason, it is recommended you create a new storage account/container for Polytomic to use. When creating a new storage account, enable the "Hierarchical Namespaces" feature on the Advanced setting tab.
You can read more about creating or migrating existing accounts on the Azure Support Portal.
You will need to enter the following values in Polytomic:
- Azure Storage account name - the account name that contains the container Polytomic will write to.
- Azure Storage access key - the access key associated with the storage account.
- Azure Storage container name - the container that Polytomic will write to.
Modifying table retention policy
When syncing to Databricks using Polytomic's bulk syncs (i.e. ELT workloads), you can override the default Databricks table retention period by turning on the Configure data retention for tables setting at the bottom of your Databricks connection configuration:
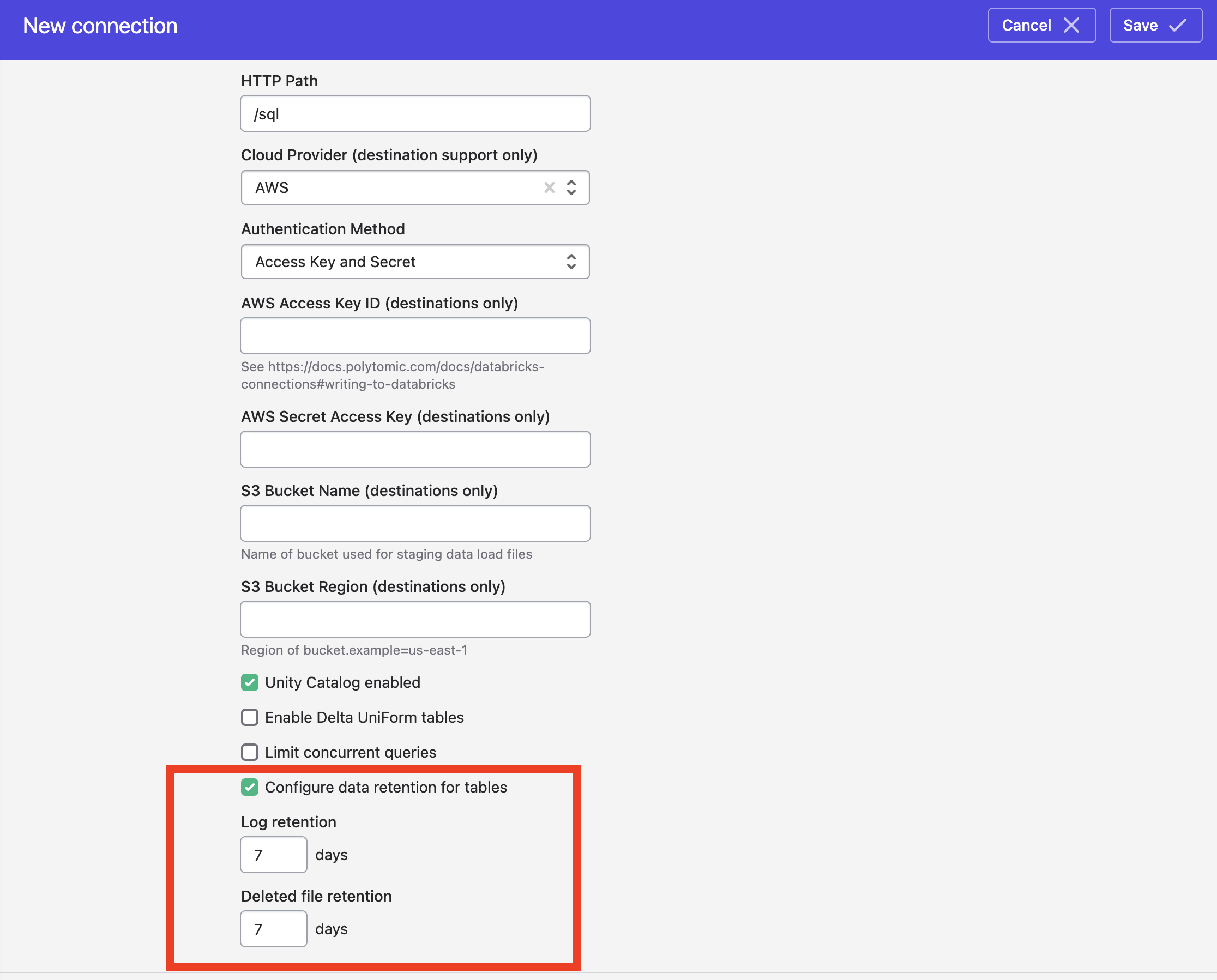
Per-sync table retention policy
You can override the global retention policy per bulk sync by going to Advanced settings at the bottom of your bulk sync configuration and turning on the Configure data retention for tables setting:

This will override whatever you have set in your Polytomic Databricks connection config.
Advanced: limiting concurrent queries on Databricks
You can choose to limit the number of concurrent queries Polytomic issues on Databricks by turning on the Concurrency query limit option. This will allow you to enter an integer limit of concurrent queries that Polytomic can issue:
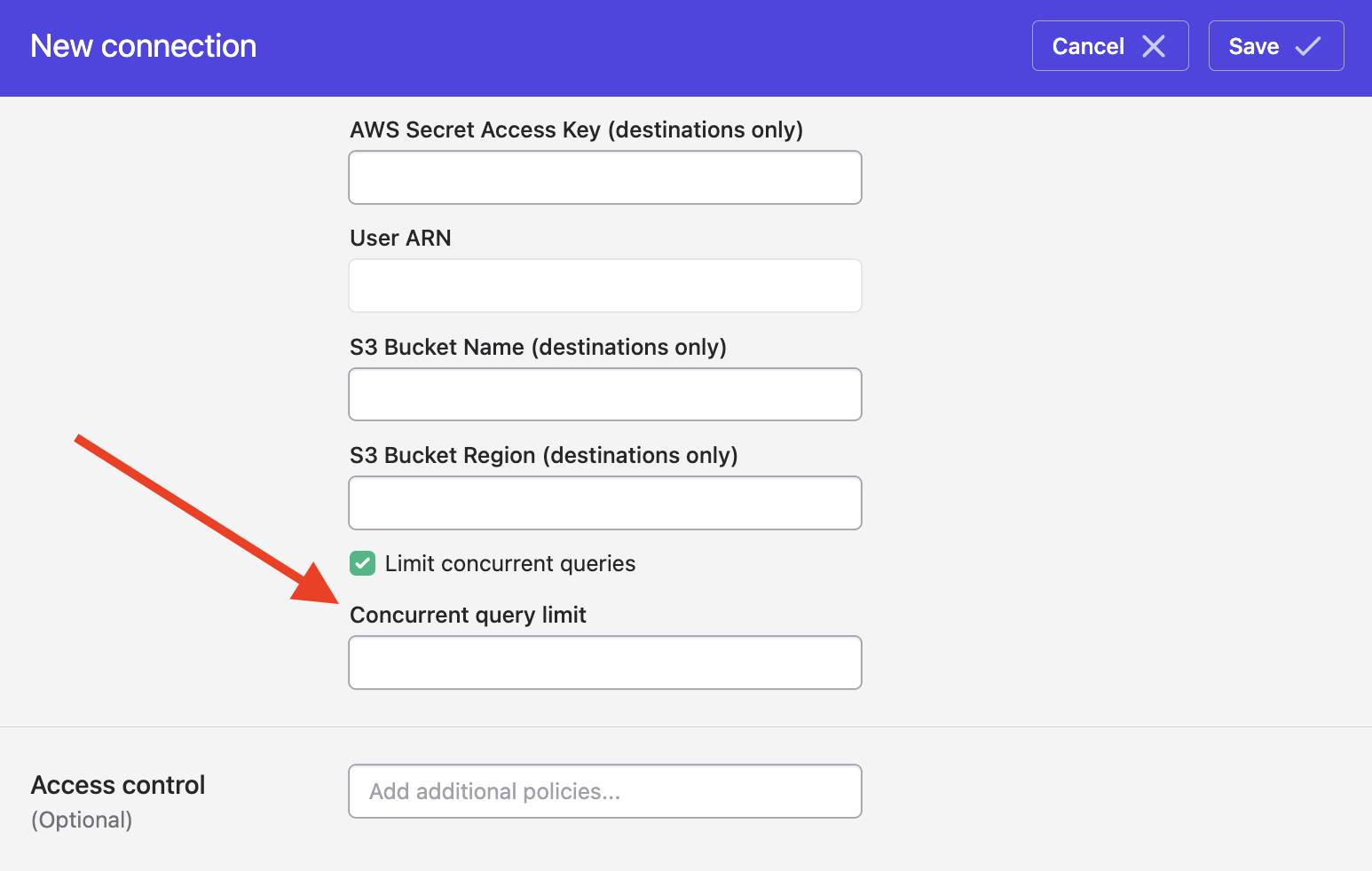
Unless you have a good reason for setting this, you should leave the option unset. During your operation of Polytomic, there are a couple of signs that would indicate the need to set a limit:
- An occasional
failed to execute query: Invalid OperationHandleerror from your Databricks cluster while Polytomic is running. - Any variance in sync running times when writing data to Databricks, where occasionally a sync takes much longer than usual.
Both are symptoms of Polytomic hitting your cluster's capacity for concurrency. The way to get around this is to turn on this option, thus limiting the number of concurrent queries Polytomic issues against your Databricks cluster.
Writing to external tables
If you'd like to write to an external location that you've already set up within Databricks, you can specify this in Step 1 of your Polytomic Bulk Sync configuration:
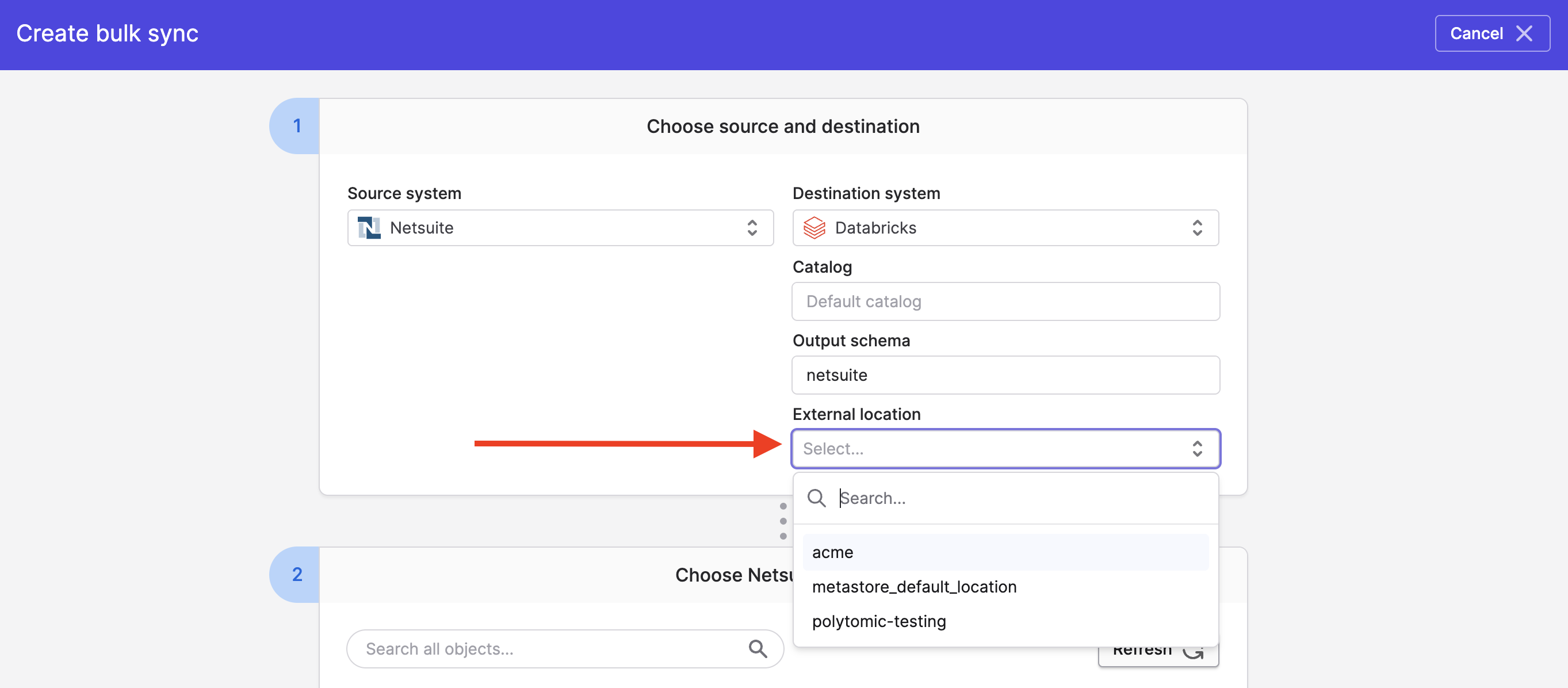
Databricks permissions
The specific Databricks permissions required vary based on whether you're reading or writing data, and if you're writing, whether you're using an external location.
Reading from Databricks
The following permissions are required to read from Databricks.
USE CATALOGon any catalogs you wish to access.USE SCHEMAon any schemas you wish to access.SELECTon any tables you wish to access.
Writing to Databricks
In addition to the permissions required for reading, the following permissions are required to write to Databricks.
CREATE SCHEMAon catalogs you are writing to.CREATE TABLEon catalogs and any existing schemas you are writing to.MODIFYon existing schemas and tables you are writing to.
Polytomic will create new schemas and tables as needed; Polytomic's user will be owner of any newly created schemas and tables.
If you are writing to tables stored in an external location, the following additional permissions are required.
CREATE EXTERNAL TABLEon the external location and associated storage credential.READ FILESon the external location.READ VOLUMEon the associated volume, if any.