Table and column naming
Default name normalization
When writing table and column names to data warehouses, databases, and cloud storage using Bulk Syncs, Polytomic's default behaviour (see next section for how to turn this off) emulates a naming convention that is common when specifying database schemas: the only valid characters are alphanumeric and underscore characters with consistent casing (lowercase except for Snowflake which employs uppercase as a convention).
The source name is thus converted to match the above rule:
- The source name is lowercased (except when writing to Snowflake where it's uppercased to follow Snowflake convention).
- Separate words in the source name are concatenated with an underscore. For example:
LoginID,loginID,Login IDall becomelogin_idin your destination. However,loginidremains unchanged because there are no indicators of there being multiple words. - Combinations of letters and numbers are tokenised separately with underscore separation:
100percentbecomes100_percent. - Multiple underscores are replaced with a single underscore. For example:
custom_salesforce_value__cbecomescustom_salesforce_value_c. - All non-alphanumeric sequences are replaced with a single underscore. For example:
From fieldbecomesfrom_field.
Turning off name normalization
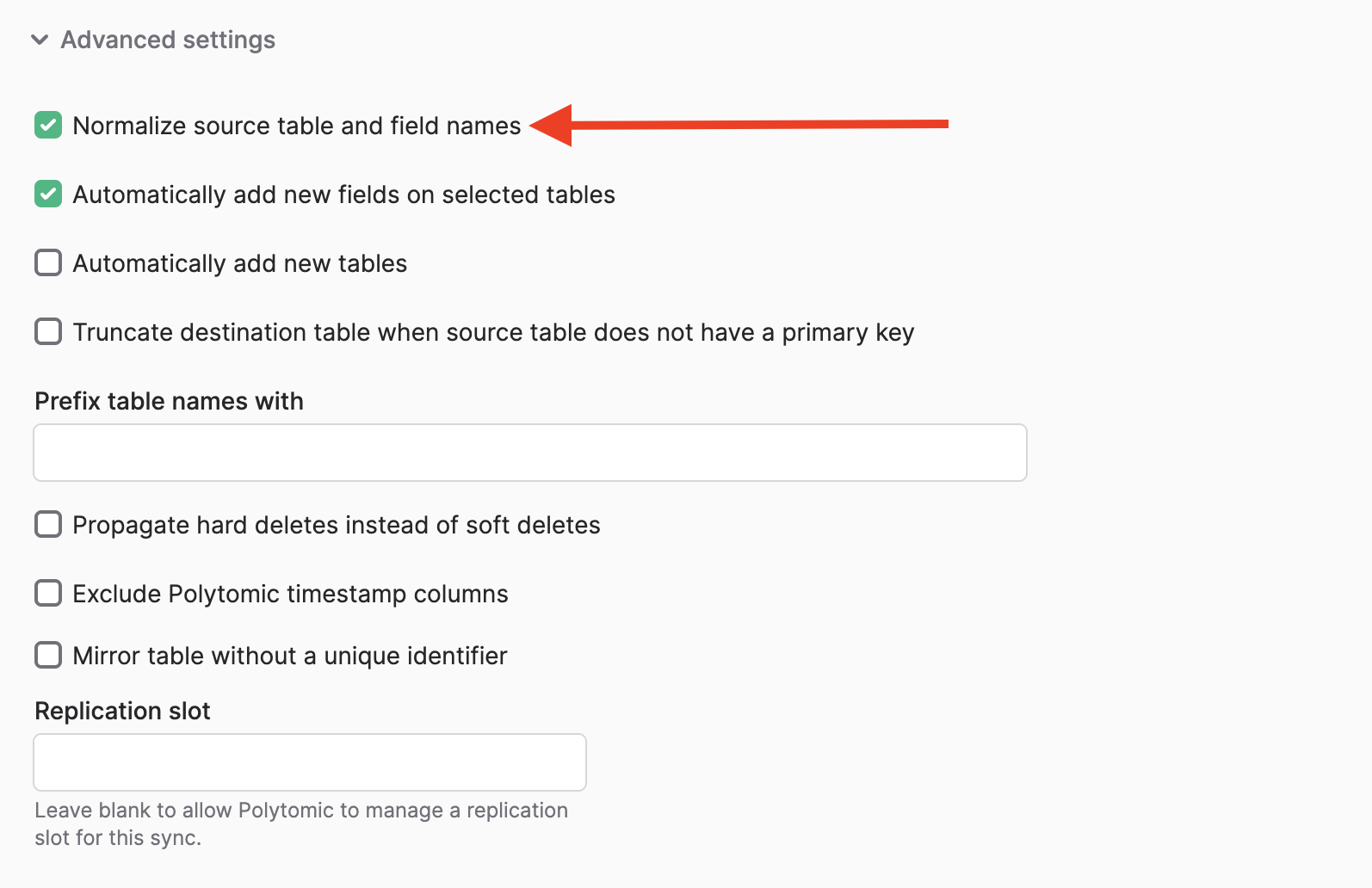
You can turn off Polytomic's name normalization by scrolling to the Advanced settings at the bottom of your Bulk Sync configuration.
Turning this off means that Polytomic will use the literal source names for your destination tables and columns (although uppercasing will remain only for Snowflake, per convention on that platform). This also means that any characters in the source name that are illegal in your destination warehouse will result in errors during your sync.
Resolving name collisions
What if two names normalize to the same one? For example, per the above rules, login_id and login__id should both normalize to login_id. In this case, to avoid name collisions Polytomic will append underscores to the colliding name until it becomes unique. Thus in this example, login__id will become login_id_.
Specifying your own output names
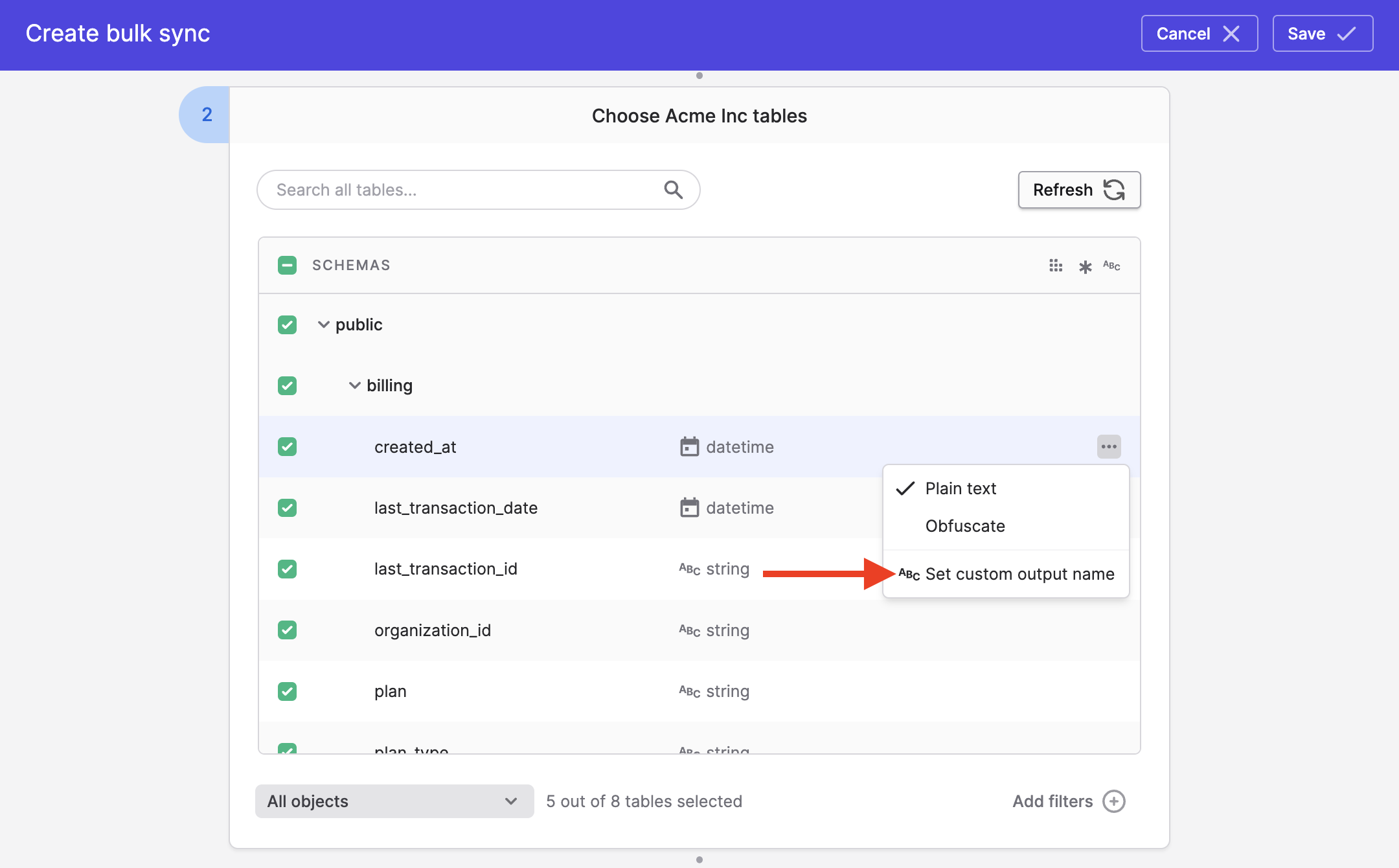
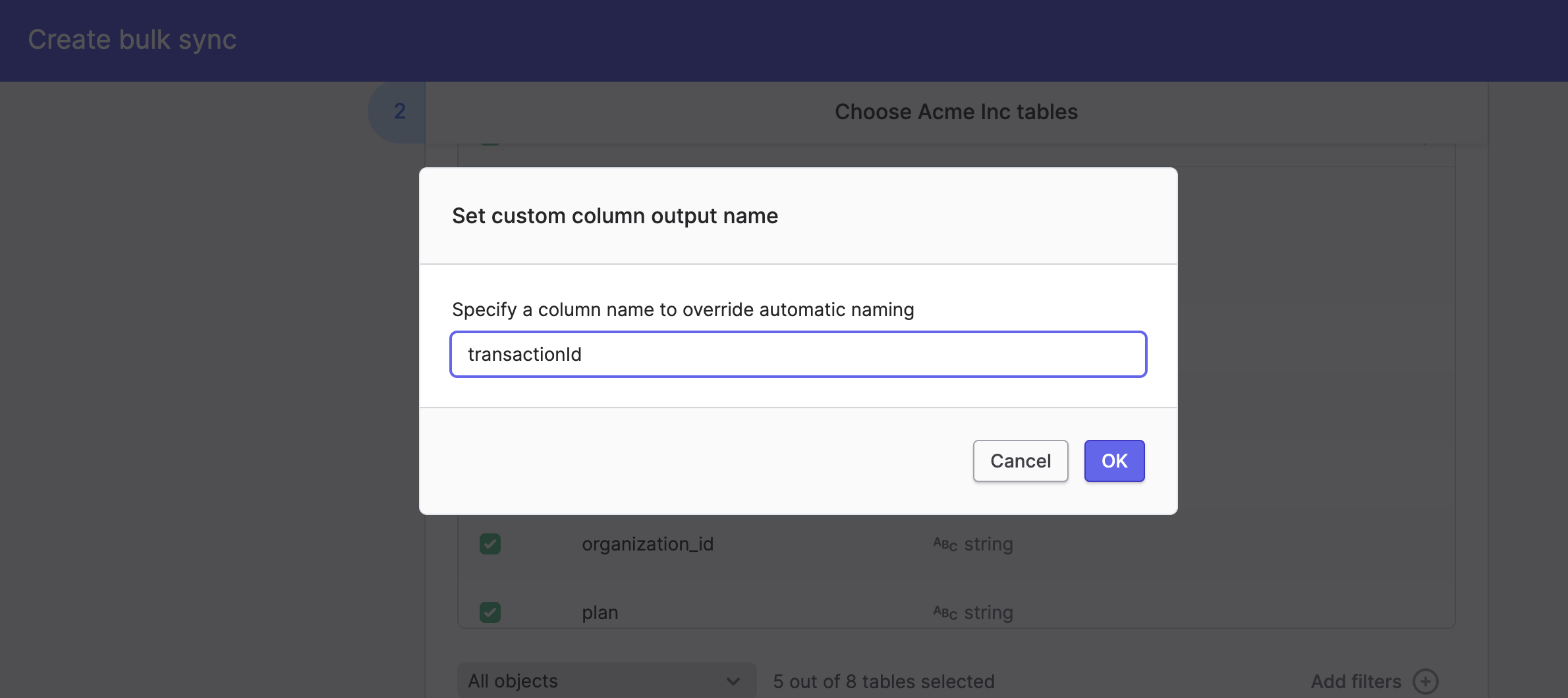
You can specify your own output name for both tables and columns to override the above. To do so, go to your bulk sync configuration and click on Set custom output name on the table or column you want a custom output name for.
No normalization for custom output namesPolytomic will apply your custom output name literally with no normalization. This includes no default uppercasing when writing to Snowflake, so if you want your custom table/column name to be uppercased in Snowflake (or you want to be able to refer to it without surrounding quotes) be sure to enter it in Polytomic as such.
Specifying custom column output names
Specifying custom table output names

Updated about 1 month ago