Google BigQuery
Source and destination
Connection methods
Polytomic connects to Google BigQuery using one of two methods:
- Service Account Key (this is most common - see section below).
- Workload Identity Federation (available on the Enterprise plan - see this page for instructions).
Connecting with a Service Account Key
-
Go to this link in your BigQuery console to create a new service account.
-
Select the project you need Polytomic to access.
-
Click the email address of the service account that you want to create a key for.
-
Click the Keys tab.
-
Click the Add key drop-down menu, then select Create new key.
-
Select these BigQuery roles:
- BigQuery Job User
- BigQuery Data Viewer
- BigQuery Metadata Viewer
- BigQuery Data Editor (if you plan on writing to BigQuery).
- Select JSON for Key type:

- Click Create and save the JSON key file.
- In Polytomic, go to Connections → Add Connection → Google BigQuery.
- Upload the JSON service account key from step 3 to Polytomic's Service account credentials field.
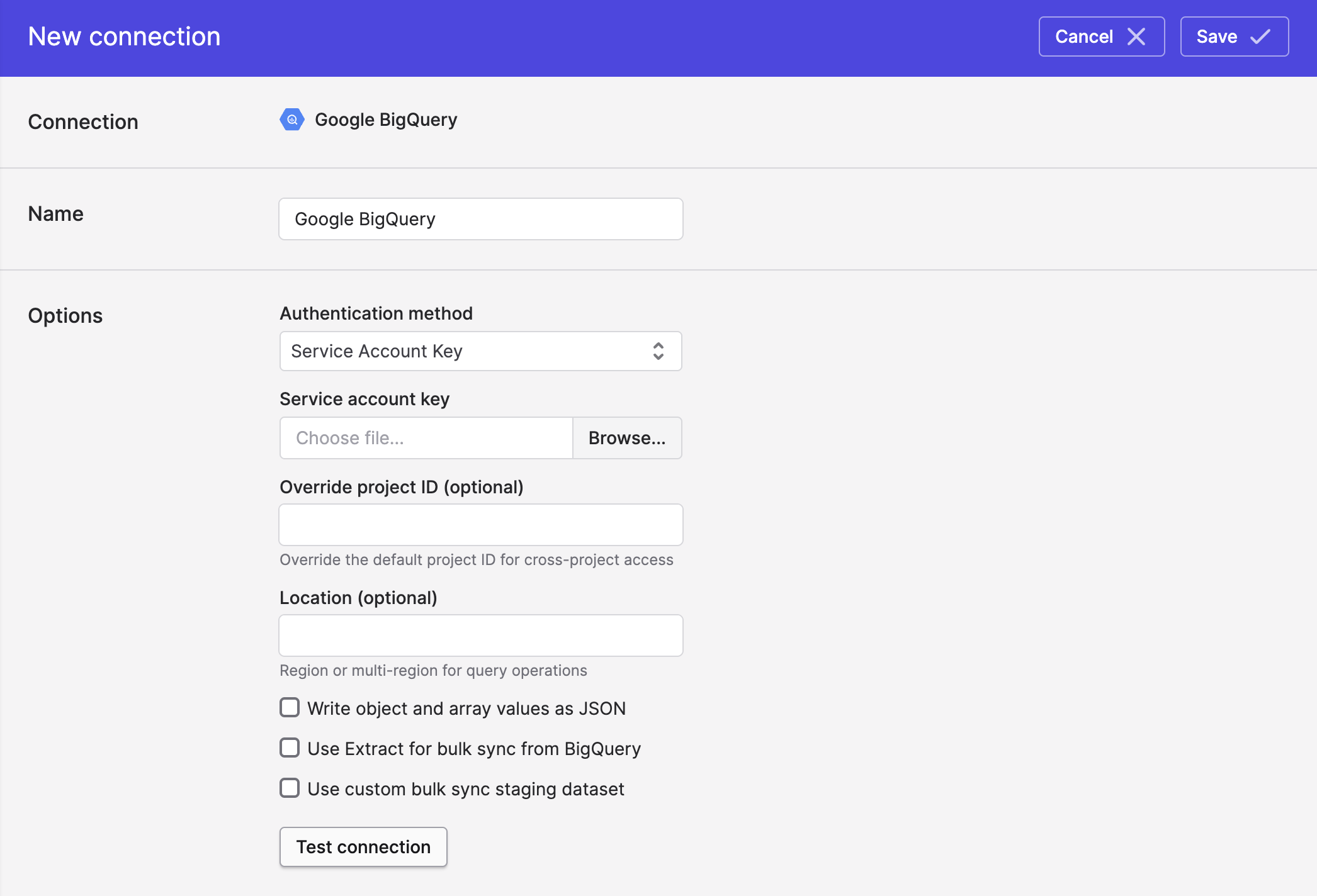
- Optional: you can fill in the Location field if you want to restrict Polytomic to creating data in a particular region (for example:
EU). - Click Save.
Configuring BigQuery with a GCS bucket
One way to improve read performance out of BigQuery is configure Extract support for BigQuery. This involves setting up a GCS bucket for BigQuery to dump query results into. It is only used when BigQuery is used as a source in a bulk sync.
- Create or identity a GCS bucket you'd like to use for temporary result storage.
- Give the service account
listandwritepermissions on the bucket. - Check the
Use Extract for bulk sync from Bigquerycheckbox. - Enter the GCS bucket name and click Save.
- Syncs started after the save will automatically use BigQuery's extract functionality.
Syncing from BigQuery
Model Syncs
Use Polytomic's Model Syncs to sync from BigQuery to other SaaS apps, spreadsheets, or webhooks (i.e. the 'Reverse ETL' pattern).
Use Bulk Syncs to sync from BigQuery to other data warehouses, databases, and cloud storage buckets like S3.
Syncing to BigQuery
Bulk syncs
Use Polytomic's Bulk Syncs to sync data to BigQuery (i.e. using the ELT pattern) from your databases, data warehouses, SaaS applications, spreadsheets, and cloud storage buckets like S3.
Writing Record types to BigQuery
Record types to BigQueryif you are trying to write Record types to BigQuery, Polytomic may modify field names in order to comply with BigQuery field naming rules. The following rules apply:
- Only the first 300 characters are used.
- Field names consist of only upper/lowercase letters, numbers, and underscores.
-,.,_.- All other characters are dropped.
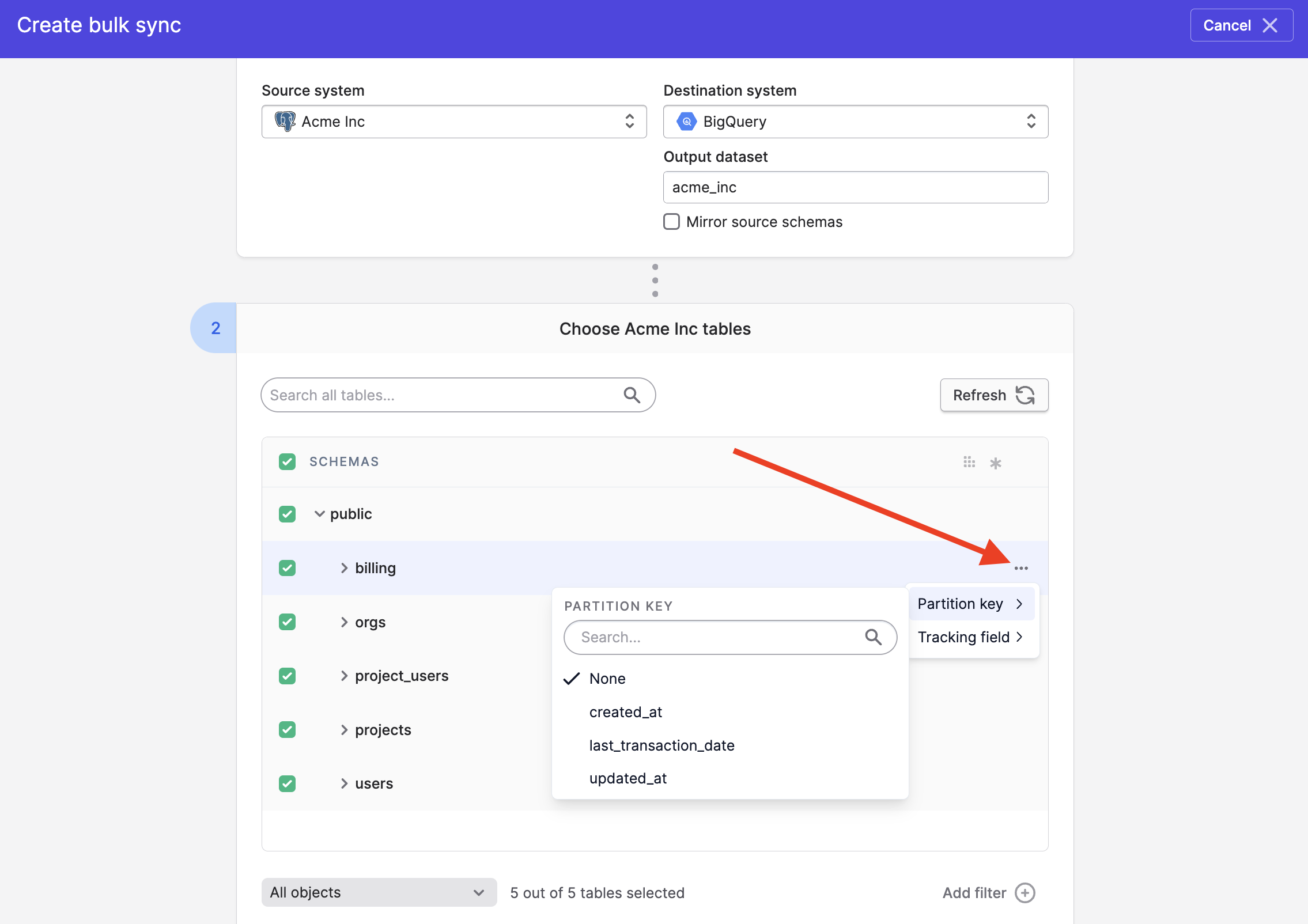
Setting partition keys
When using our Bulk Syncs feature to write data to BigQuery, you have the option of setting a partition key on each table. While optional and usually unneeded, doing so is recommended for large data sets (e.g. in-app event streams). Setting a partition key will increases your query speed on the resulting data.
You can set partition keys on each table by clicking on the 'more' button on each table in your bulk sync config as shown in this screenshot:
Propagating deletes to BigQuery
Tracking fields and deletesWhen syncing from databases and data warehouses, deletes will not propagate for tables with tracking fields set, no matter what the setting below is set to.
As with all data warehouses, Polytomic offers two options for propagating deletes to BigQuery:
- Soft deletes
- Hard deletes
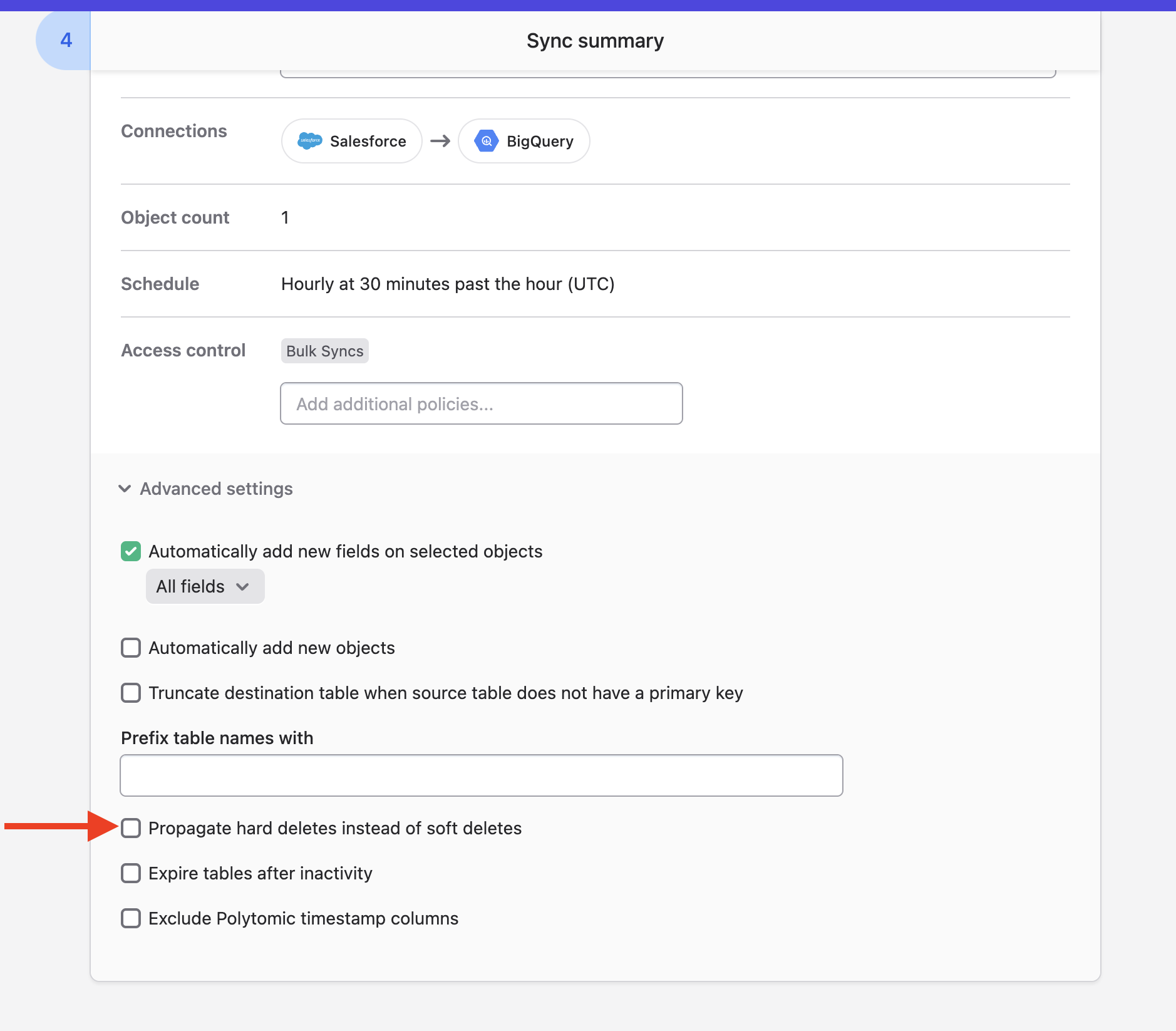
By default, Polytomic will propagate deletes from your source as soft-deletes, by marking the __polytomic_deleted_at column for each table with a datetime reflecting deletion time.
You can choose to replace this behaviour by propagating deletes as hard deletes instead. To do so, simply check the Propagate hard deletes instead of soft deletes checkbox in the Advanced settings option at the bottom of your sync configuration:
Expiring tables after inactivity
Polytomic can automatically expire all BigQuery tables used in a bulk sync after a certain period of inactivity. To enforce this, turn on the Expire tables after inactivity advanced setting:
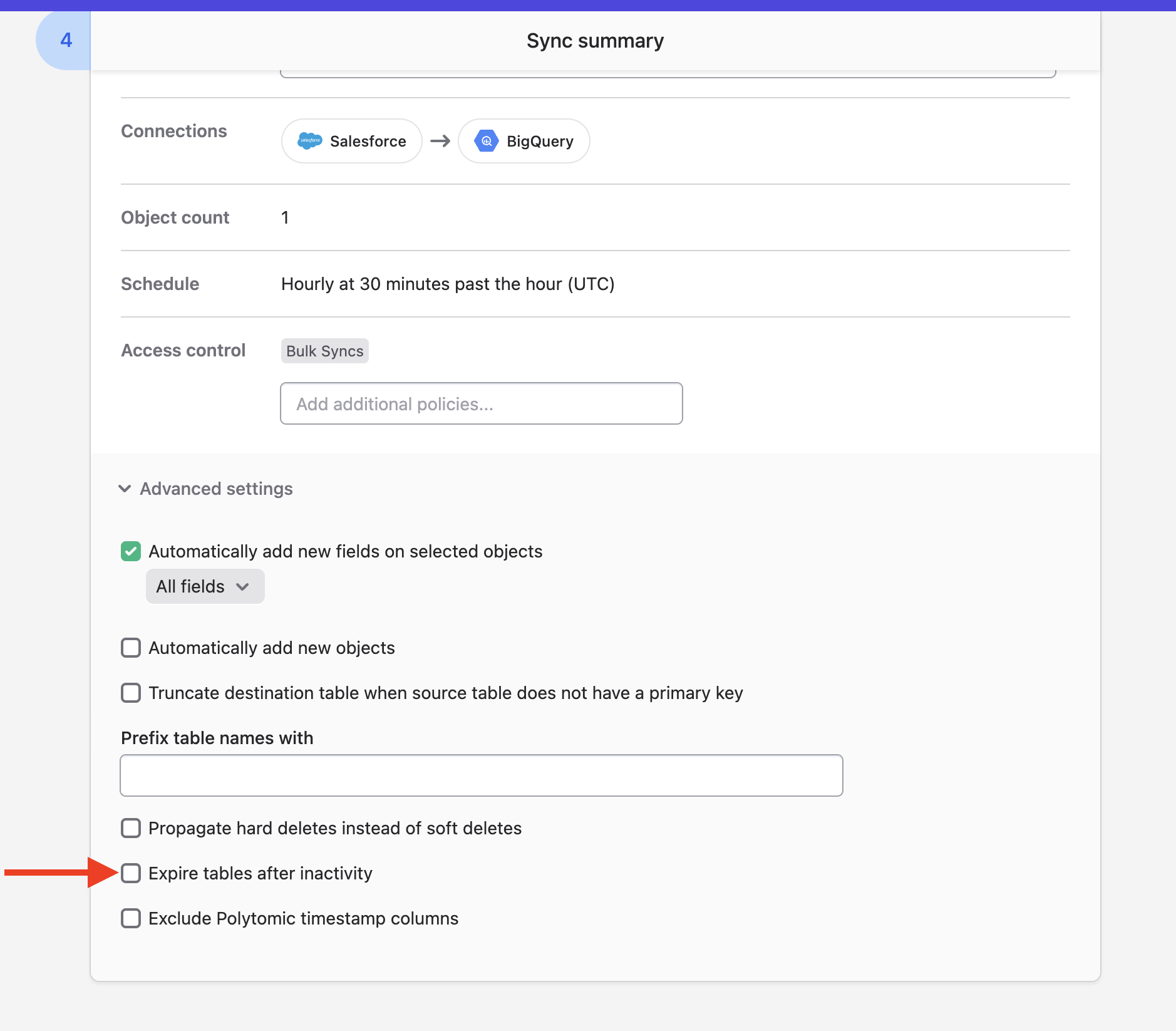
You will then be prompted to enter a number of days after which expiration will take place:
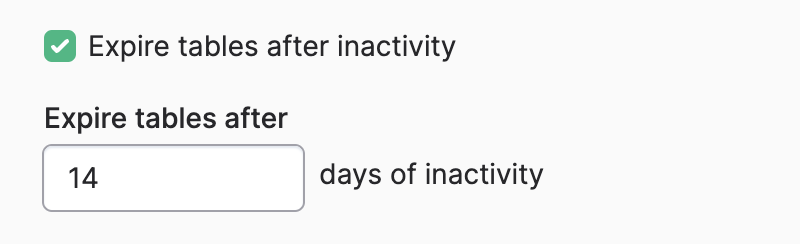
Note that every time the sync runs Polytomic will reset its internal day counter to zero and restart the expiration window countdown.
Updated 23 days ago